
Here is a presentation with the information on this post:
https://speakerdeck.com/diogogcunha/dot-net-template-solution-architecture
The main objective is to have a solution that is
- Flexible to change, add and remove features
- Maintanable for many developers with different coding habits
- Sustainable for growth
- Understandable for code review and optimization
- Easy to add new features with few lines of code without losing structure
- Testable (unit and integration)
The basis for this architecture will follow the typical 3 layered solution

So the Frontend is only dependent on the Services Layer and the Services Layer is only dependent on the Data Layer. The Frontend shouldn't be able to call Data Layer objects without passing through the Services Layer logic.
Let's go bottom-up!
Data Layer
namespace projName.DataThis layer would be a new Project inside the solution and it is an abstraction for the data that the system writes and reads from different data sources. It should only contain CRUD logic and nothing else.

Repositories and entity objects should be here.
Entities
Entities are the raw domain objects that come from the data source. So if you are integrating with and external platform such as Facebook or if you are writing on a XML you should have that information in object classes so you have strongly typed entities.
A lot of .Net developers will use EntityFramework to do most of the work writing to the database. Using model first this is the place to put the .edmx file, using code first this is where you’ll put your DbContext file and your entities.
To be able to mock the DbContext or the ObjectContext you should do a wrapper around it (or a partial class) that use an interface and expose what you need.
Avoid unecessary dependecies using different projects under the same namespace.

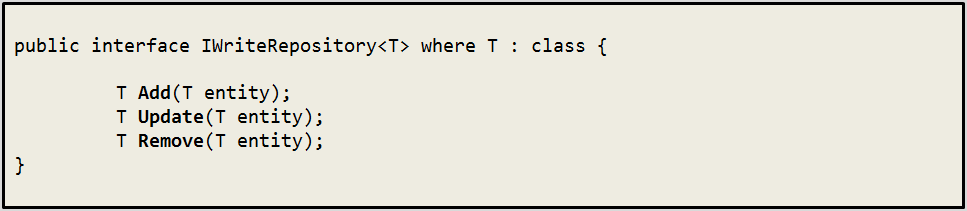
Repositories
namespace projName.Data.Core.Repositories
All repositories must have their own interface and class and it is useful to have some generic abstract repositories to decrease the amount of code to be written.
Repository methods should be easily overriden for flexibility so we could make them virtual but it’s not mandatory because C# let’s you override a method with the [new] word on the function signature.

Read repository is probably the most used one, so we should try to make it as powerfull as possible. Also because LINQ is cool I’m copying some of it’s namings.

In some situations the Update method is not necessary (if you use EntityFramework for some of your data) so don’t feel that obligated to implement this method, just leave the possibility there for other data sources that might need it.
Services Layer
namespace projName.Services
Services should be divided by actions oriented and also reading services or writing services, this will allow all writing services to be dependent on their corresponding reading services if needed (example: instead of a UserService use UserInfoService, UserEditService and UserAuthService)
External modules should be added to avoid unwanted dependencies to the main .dll file

Unit of Work (Service Layer and DataLayer)
namespace projName.Data.UnitOfWork
Every service that needs to access the Data Layer will extend this class and (as the repositories) have it's own interface.

This should be implemented on a different Project so that when you reference the Services on the Frontend you don’t have access to the Unit of Work.

View Models
namespace projName.ViewModels
Services only receive and return ViewModel objects that should have Frontend needs in mind and not domain entities to make them aligned with the operations they refer to.
Dividing the ViewModels into folders according to the entities they refer to will make the code more maintainable.
Mapping Entities to ViewModels and the other way around is probably the most boring code to write because it’s simply transforming one object to another one, so I usually use AutoMapper which is a very handy tool.
There are several ways to do these mappings and I believe that the big concern here is performance and easily understand to which ViewModels does a Entity map to and how that mapping is processed, and the other way arround.

Frontend layer
namespace projName.Frontend
It should be as easy to use a MVC.Net project on top of this architecture as it would be to use WebForms, WinForms or a Mobile App.
Again it is important to have clear namespaces in order for the project to grow if necessary so use names like Frontend.Website, Frontend.Mobile or Frontend.Backoffice

The end for now!!!
I think this is a nice solution because it already saved me from many situations of late requirements, weird integrations or pure stupidity from the part of the client or idiotic solution sugestions from managers because it has a lot of flexibility but it's still very simple to maintain and extend.
I've been told that it pretty much follows the Onion Architecture and from what I've read of it has the same principles! (thanks Nuno Costa for the cool input!)
Sem comentários:
Enviar um comentário